DTBot 的“表格清洗器”智能体,支持用户通过自然语言直接对单个表格文件(CSV/XLSX/XLS)进行整理、筛选、去重、排序与汇总处理,无需手写 SQL,也不需要额外编写脚本。用户只要输入一句接近日常表达的提示词,系统就能自动理解需求,并生成可执行的单表清洗方案,完成对原始表格数据的结构化整理。
这套能力专注于“单表场景下的数据清洗与整理”,特别适用于以下类型的需求:
列操作:列的增删,列的顺序调整,列的重命名,列的拆分与合并。
行操作:行的筛选与删除,行的排序,行的去重与找重复数据,取TopN记录。
统计操作:分组聚合统计,条件统计,去重统计,重复数据统计,排序统计,TopN统计。
窗口操作:行内排名,分组内 TopN, 分组内累计计算,前后行对比,分组内占比。
这项能力更像一个“自然语言驱动的单表数据整理助手”。用户只需要描述想怎么整理这张表,系统就能自动完成相应的数据清洗与整理操作,无需掌握 SQL 或复杂的数据处理流程。它特别适合日常办公、运营分析、台账整理和基础数据预处理等场景。
一、配置以及输入输出说明
在工作流编辑界面中,位于左侧 「文件处理」 分类下的 「表格清洗器」 节点。如下图:
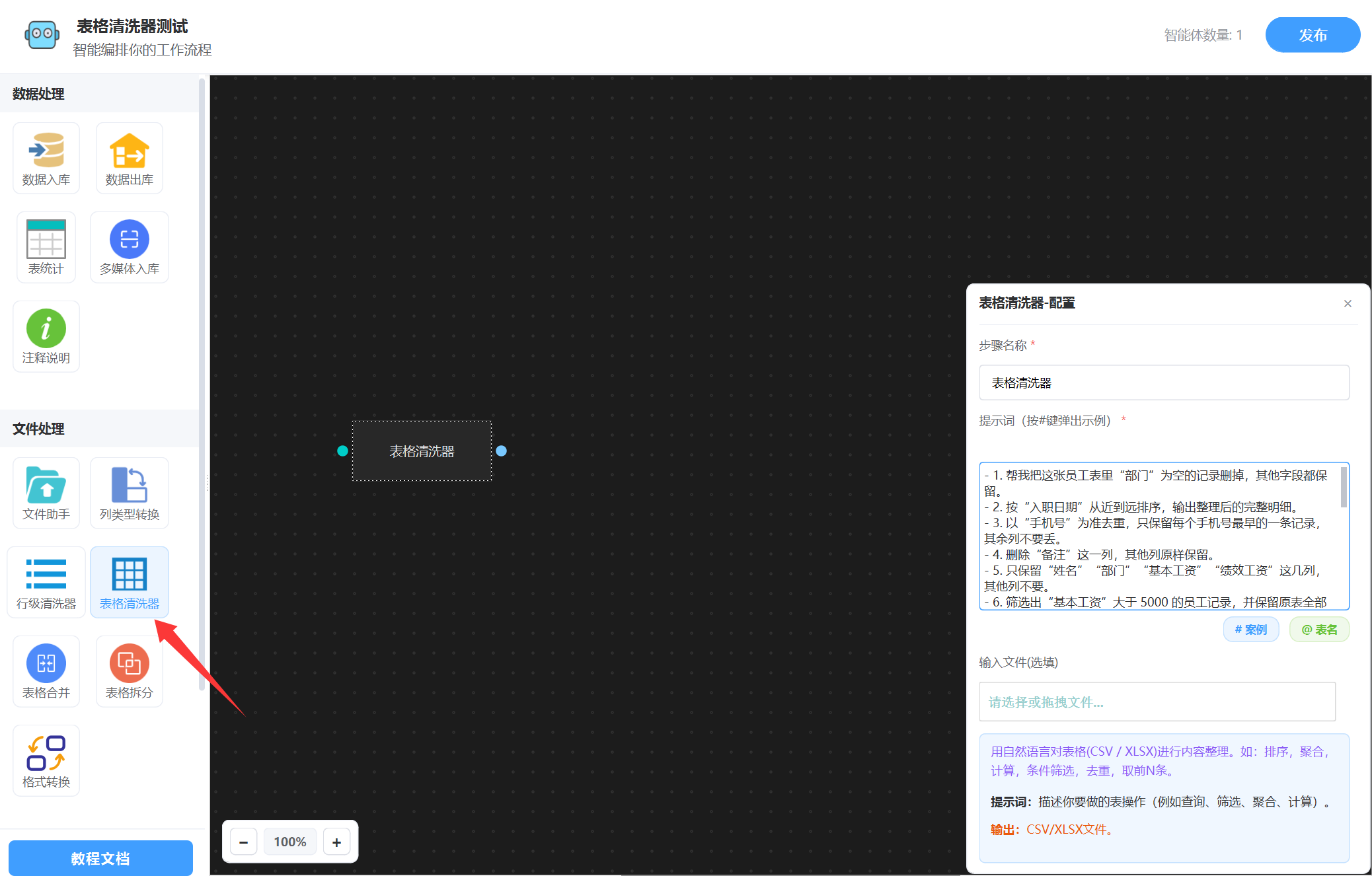
输入参数
- 提示词: 清洗的提示词描述。
- 输入文件: 选填,(CSV/XLSX),支持多个,不填就取上一个智能体的输出文件。
- 输出目录: 选填,清洗后的文件存放位置,不指定就默认在系统工作流目录。
输出
清洗后的CSV文件列表。
二、功能与案例提示词
1. 列操作
1.1 列的增删
删除列:移除不需要的列。
*****案例提示词*****
1. 删除“备注”列。
2. 删除“备注”,“手机号”列。
3. 保留“用户姓名”,“用户ID”。
新增列:新增一列,可以是空列,也可以基于已有列计算得出。
*****案例提示词*****
1. 新增一列“备注”,这一列先全部留空。
2. 新增一列“工资合计”,结果等于“基本工资”加上“岗位工资”。
3. 在“入职日期”列右边新增“工龄标签”列,如果入职时间在 2025年到今天以内标记为“新员工”,否则标记为“老员工”。
1.2 列的顺序调整
移动列:将某列向左或向右移动,改变列的前后位置。
*****案例提示词*****
1. 将“手机号”列移动到“姓名”列后面。
2. 将“用户ID”列与“用户姓名”列交换。
1.3 列的重命名
修改列名:将列标题改为更清晰或更符合需求的名称。
*****案例提示词*****
1. 将“用户ID”列改成“用户编号”。
1.4 列的拆分与合并
拆分列:按分隔符(如逗号、空格)或固定宽度,将一列拆分成多列。
*****案例提示词*****
1. 将“开户地址”列按空格拆分成“省”“市”“区”三列,原始“开户地址”列要保留。
合并列:将多列的内容按指定连接符合并成一列。
*****案例提示词*****
1. 将“省”“市”“区”三列用“-”连接,合并成新列“详细地址”。
2 行操作
2.1 行的筛选与删除
删除不符合条件的记录:按指定条件移除不需要的行。
*****案例提示词*****
1. 删除“用户ID”列为空的记录。
2. 删除“基本工资”小于 5000 的员工记录。
3. 删除“在职状态”为“离职”的记录。
保留符合条件的记录:只保留满足条件的行,其余行不输出。
*****案例提示词*****
1. 只保留“部门”为“销售部”的记录。
2. 只保留“基本工资”大于 8000 的员工记录。
3. 只保留“入职日期”在 2025-01-01 之后的记录。
2.2 行的排序
按条件排序:根据某一列或多列的值对行重新排序。
*****案例提示词*****
1. 按“基本工资”从高到低排序。
2. 按“入职日期”从近到远排序。
3. 先按“部门”升序,再按“基本工资”降序排序。
2.3 行的去重与重复筛出
去重:按某列或某几列判定重复,只保留一条记录。
*****案例提示词*****
1. 按“用户ID”去重。
2. 按“手机号”去重,只保留每个手机号一条记录。
3. 按“用户姓名”和“身份证后四位”组合去重。
找出重复数据:筛选出重复出现的记录,保留所有命中的重复行。
*****案例提示词*****
1. 找出“用户ID”列重复的数据。
2. 筛选出“手机号”重复的记录。
3. 找出“用户姓名”和“身份证后四位”同时重复的记录。
2.4 行数限制
截取前几条记录:按排序结果或原始顺序,只保留前 N 条数据。
*****案例提示词*****
1. 取前 5 条记录。
2. 按“基本工资”倒序排序后,取前 10 条。
3. 按“入职日期”从近到远排序,只保留前 20 条。
2.5 多条件组合行处理
按多个条件依次处理记录:对同一批数据同时执行筛选、重复判断、排序、截取等操作。
*****案例提示词*****
1. 删除“用户ID”为空的记录后,找出“用户ID”重复的数据。
2. 筛选出“基本工资”大于 5000 的员工记录,再按“基本工资”倒序排序。
3. 找出“手机号”重复的数据,按“入职日期”从近到远排序,取前 10 条。
3 统计操作
3.1 基础聚合统计
对单表中的数值、数量进行汇总统计。
*****案例提示词*****
1. 统计表总数。
2. 统计“基本工资”的总和。
3. 统计“岗位工资”的平均值。
3.2 分组统计
按某个字段或多个字段分组后,对每组分别统计。
*****案例提示词*****
1. 按“部门”分组,统计每个部门的人数。
2. 按“班组”分组,统计每个班组的平均工资。
3. 按“在职状态”和“部门”分组,统计各组员工数量。
3.3 条件统计
在满足指定条件的记录范围内做统计。
*****案例提示词*****
1. 统计“在职状态”为“在职”的员工人数。
2. 统计“基本工资”大于 8000 的员工数量。
3. 统计“部门”为“销售部”的员工工资总和。
3.4 去重统计
按去重后的记录口径进行计数或统计。
*****案例提示词*****
1. 按“用户ID”去重后,统计总人数。
2. 按“手机号”去重后,统计员工数量。
3. 按“用户姓名”和“身份证后四位”组合去重后,统计记录数。
3.5 重复数据统计
对重复记录进行统计分析。
*****案例提示词*****
1. 统计“用户ID”重复的数据有多少条。
2. 统计“手机号”重复的记录数量。
3. 统计“用户姓名”和“身份证后四位”同时重复的记录数。
3.6 排序统计结果
对统计结果按指标大小进行排序。
*****案例提示词*****
1. 按“部门”分组统计人数,并按人数从高到低排序。
2. 按“班组”分组统计平均工资,并按平均工资倒序排序。
3. 按“在职状态”分组统计人数,并按人数升序排序。
3.7 Top N 统计
对统计结果或明细结果取前 N 条。
*****案例提示词*****
1. 按“部门”分组统计人数,取人数最多的前 5 个部门。
2. 按“班组”分组统计平均工资,取前 10 个班组。
3. 按“基本工资”倒序排序,取前 20 名员工。
3.8 多条件组合统计
对同一批数据同时执行筛选、分组、排序、截取等统计操作。
*****案例提示词*****
1. 筛选出“基本工资”大于 5000 的员工后,按“部门”分组统计人数。
2. 删除“在职状态”为“离职”的记录后,按“班组”分组统计平均工资,并按平均工资倒序排序。
3. 找出“用户ID”重复的数据后,按“部门”分组统计重复记录数量,取前 10 个部门。
4 窗口操作
4.1 行内排名
按某一列或某几列分组后,在每组内部按指定顺序进行排序、编号或排名。
*****案例提示词*****
1. 按“部门”分组,按照“基本工资”从高到低给每个员工生成组内排名。
2. 按“班组”分组,按照“入职日期”从早到晚给每条记录生成组内顺序编号。
3. 按“城市”分组,按照“销售金额”从高到低计算每条订单在本城市内的排名。
4.2 分组内 Top N
在每个分组内部,按指定排序规则取前 N 条记录。
*****案例提示词*****
1. 按“部门”分组,取每个部门“基本工资”最高的前 3 条记录。
2. 按“班组”分组,取每个班组最新的 2 条入职记录。
3. 按“城市”分组,取每个城市“销售金额”最高的前 5 条订单。
4.3 分组内累计计算
在每个分组内部,按指定顺序计算累计值。
*****案例提示词*****
1. 按“用户ID”分组,按照“交易日期”排序,新增一列“累计消费金额”。
2. 按“部门”分组,按照“入职日期”排序,新增一列“累计入职人数”。
3. 按“设备ID”分组,按照“采集时间”排序,新增一列“累计告警次数”。
4.4 前后行对比
在同一分组内,比较当前行与上一行的数据差异或变化。
*****案例提示词*****
1. 按“用户ID”分组,按照“交易日期”排序,新增一列“与上一笔交易金额差值”。
2. 按“设备ID”分组,按照“采集时间”排序,新增一列“与上一条温度差值”。
3. 按“员工ID”分组,按照“考勤日期”排序,新增一列“与上一天出勤状态是否变化”。
4.5 分组内占比
在同一分组内,计算当前记录数值占本组总量的比例。
*****案例提示词*****
1. 按“部门”分组,计算每个员工“基本工资”占本部门工资总额的比例。
2. 按“城市”分组,计算每笔订单金额占本城市总销售额的比例。
3. 按“班组”分组,计算每条记录“加班时长”占本班组总加班时长的比例。
三、提示词注意事项
编写提示词尽量注意如下情况:
1. 尽量使用表头中的真实列名。
2. 尽量把操作说清楚,例如筛选、排序、去重、找重复、删列、保留列、统计。
3. 如果有多步处理,建议按顺序分点写。
4. 如果是筛选,尽量把条件描述完整。
5. 如果是排序,尽量写清楚排序字段和方向。
6. 如果是去重,尽量写清楚按哪一列去重。
7. 如果是找重复,尽量明确写“找出重复数据”,不要只写“重复”。
8. 如果是统计,尽量写清楚按什么统计、统计什么。
9. 如果是新增列,尽量写清楚新增列名和计算规则。
10. 如果是调整列位置,尽量说明是否只改顺序、不改列值。
11. 如果结果只需要部分数据,尽量明确写“取前几条”。
12. 提示词越具体,生成结果通常越稳定。
四、总结
DTBot 的“表格清洗器”本质上是一款面向单表数据处理场景的自然语言智能助手,能够让用户无需掌握 SQL 或编写脚本,仅通过清晰的提示词描述,就完成表格文件的筛选、删改列、去重、排序、统计汇总以及组内排名、Top N、累计计算等复杂整理工作,并最终输出结构化的清洗结果文件,特别适用于日常办公、运营分析、台账整理和基础数据预处理等需要快速处理单表数据的业务场景。