今天给大家带来一个实际的案例分析:“多水果销售表合并评价数据分析”。数据量1000w行,30列。
一、需求分析
有一批水果销售表格(10个,每个文件100w行,30列,占用200MB左右),如下图:
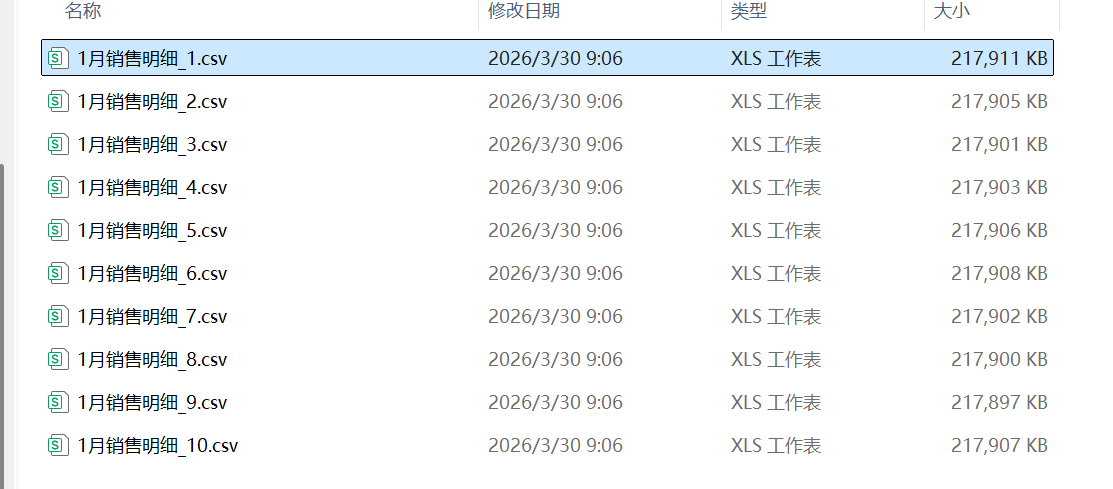
每个表有100w行数据,30列。 每个表的表头如下图:
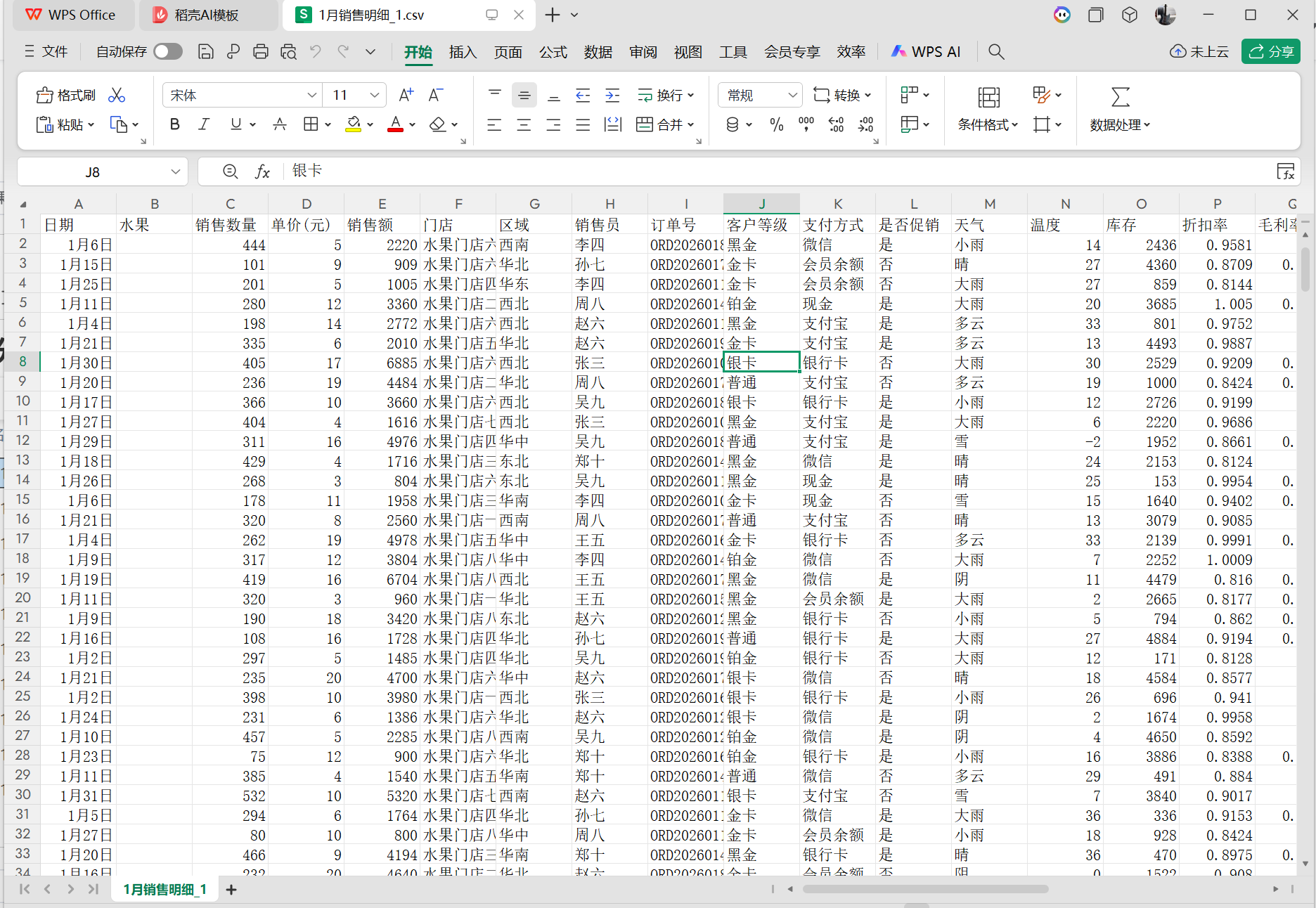
部分数据:
| 日期 | 水果 | 销售数量 | 单价(元) | 销售额 | 门店 | 区域 | 销售员 | 订单号 | 客户等级 | 支付方式 | 是否促销 | 天气 | 温度 | 库存 | 折扣率 | 毛利率 | 成本 | 会员ID | 渠道 | 仓库 | 供应商 | 批次号 | SKU编码 | 省份 | 城市 | 时段 | 节假日 | 评价分 | 退货标记 |
| 1月6日 | 444 | 5 | 2220 | 水果门店六店 | 西南 | 李四 | ORD20260184071460 | 黑金 | 微信 | 是 | 小雨 | 14 | 2436 | 0.9581 | 0.2 | 4 | VIP317543 | 门店 | 一号仓 | 供应商C | LOT785893 | SKU0147 | 福建 | 深圳 | 晚上 | 是 | 3.91 | 否 | |
| 1月15日 | 101 | 9 | 909 | 水果门店六店 | 华北 | 孙七 | ORD20260175087932 | 金卡 | 会员余额 | 否 | 晴 | 27 | 4360 | 0.8709 | 0.4444 | 5 | VIP031930 | 直播 | 前置仓 | 供应商B | LOT321350 | SKU0043 | 河南 | 广州 | 下午 | 否 | 3.99 | 否 | |
| 1月25日 | 201 | 5 | 1005 | 水果门店四店 | 华东 | 李四 | ORD20260116501947 | 金卡 | 会员余额 | 否 | 大雨 | 27 | 859 | 0.8144 | 0.2 | 4 | VIP212978 | 直播 | 三号仓 | 供应商C | LOT340708 | SKU0111 | 浙江 | 成都 | 中午 | 否 | 3.69 | 否 | |
| 1月11日 | 280 | 12 | 3360 | 水果门店二店 | 西北 | 周八 | ORD20260148950125 | 铂金 | 现金 | 是 | 大雨 | 20 | 3685 | 1.005 | 0.4167 | 7 | VIP894217 | 外卖 | 三号仓 | 供应商A | LOT935784 | SKU0028 | 山东 | 杭州 | 下午 | 否 | 3.48 | 否 | |
| 1月4日 | 198 | 14 | 2772 | 水果门店六店 | 西北 | 赵六 | ORD20260116090383 | 黑金 | 支付宝 | 是 | 多云 | 33 | 801 | 0.9752 | 0.5 | 7 | VIP975247 | 直播 | 前置仓 | 供应商E | LOT744409 | SKU0084 | 山东 | 成都 | 上午 | 否 | 3.54 | 否 |
现在需要执行如下步骤:
1. 合并子表:将10个表格先合并成一个表格,名称:“总水果销售”。
2. 清理异常:将“总水果销售”表的“水果”列为空的行删除。
3. 新增列: 在“退货标记”列右边新增“等级”列。当 评价分>=5时,取“优秀”,4-5时,取“中等”,否则取“一般”。
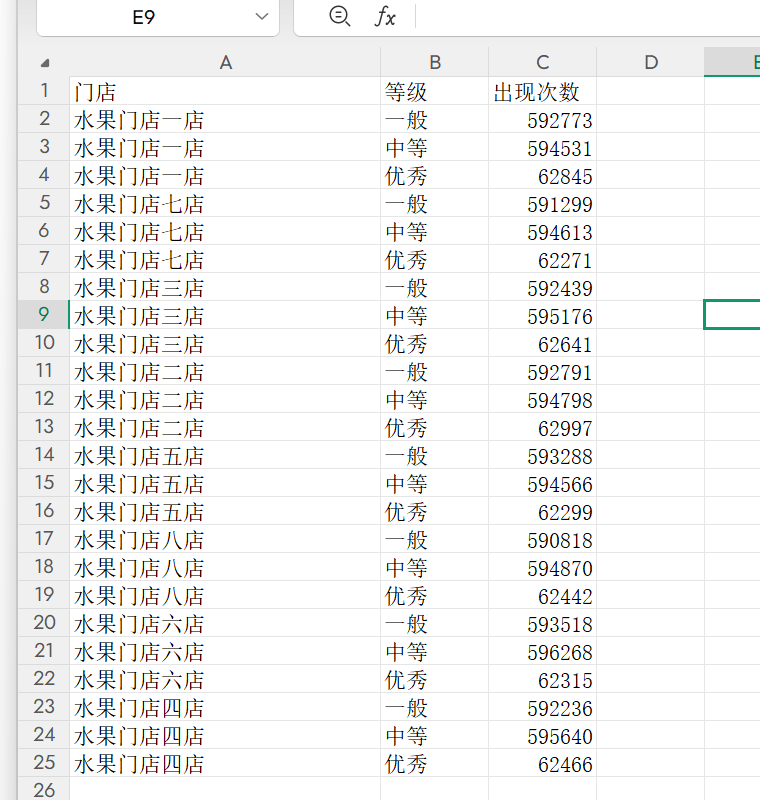
4. 分组统计: 统计每个门店,“优秀”次数,“中等”次数,“一般”次数。
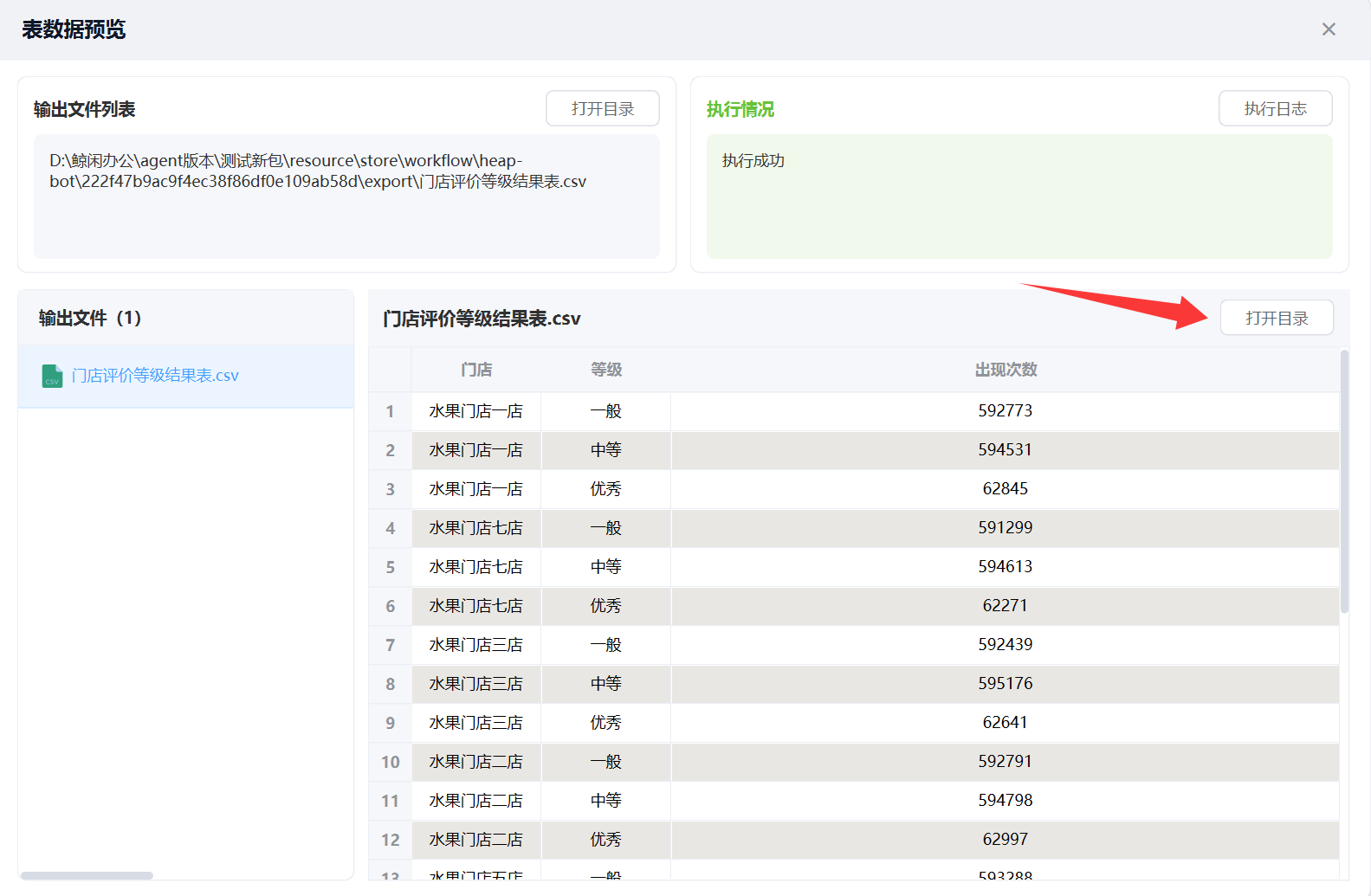
统计结果,如图:
二、工作流配置
为了完成需求,我们来详细配置下工作流。
步骤1: 获取表格文件
找到“文件助手”, 写好提示词,描述你的表格的位置。如下图:
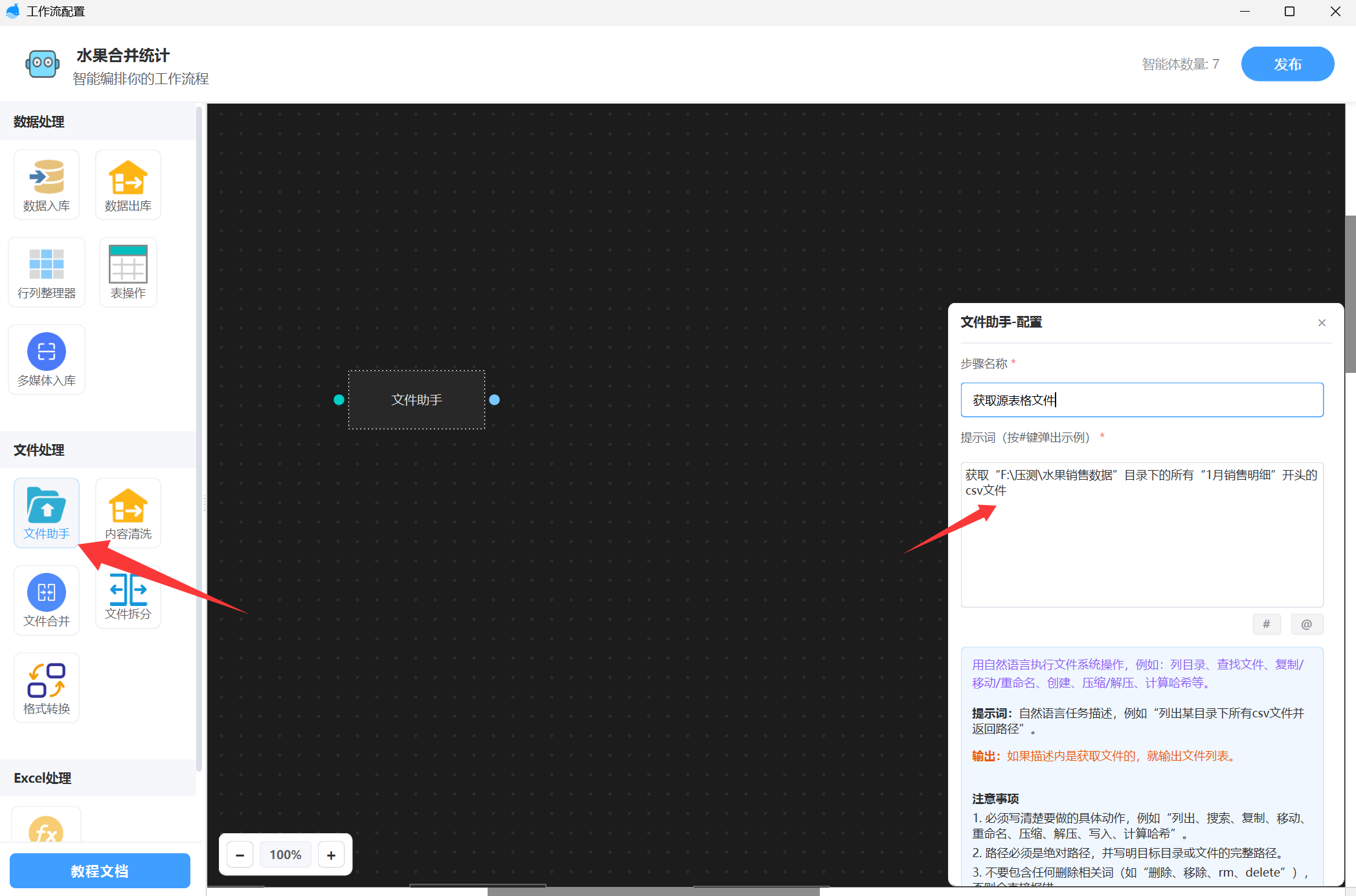
这样我们就取得了所有的输入表格原始文件。
步骤2: 合并表格
找到“文件合并”, 填写合并表格的名称。如下图:
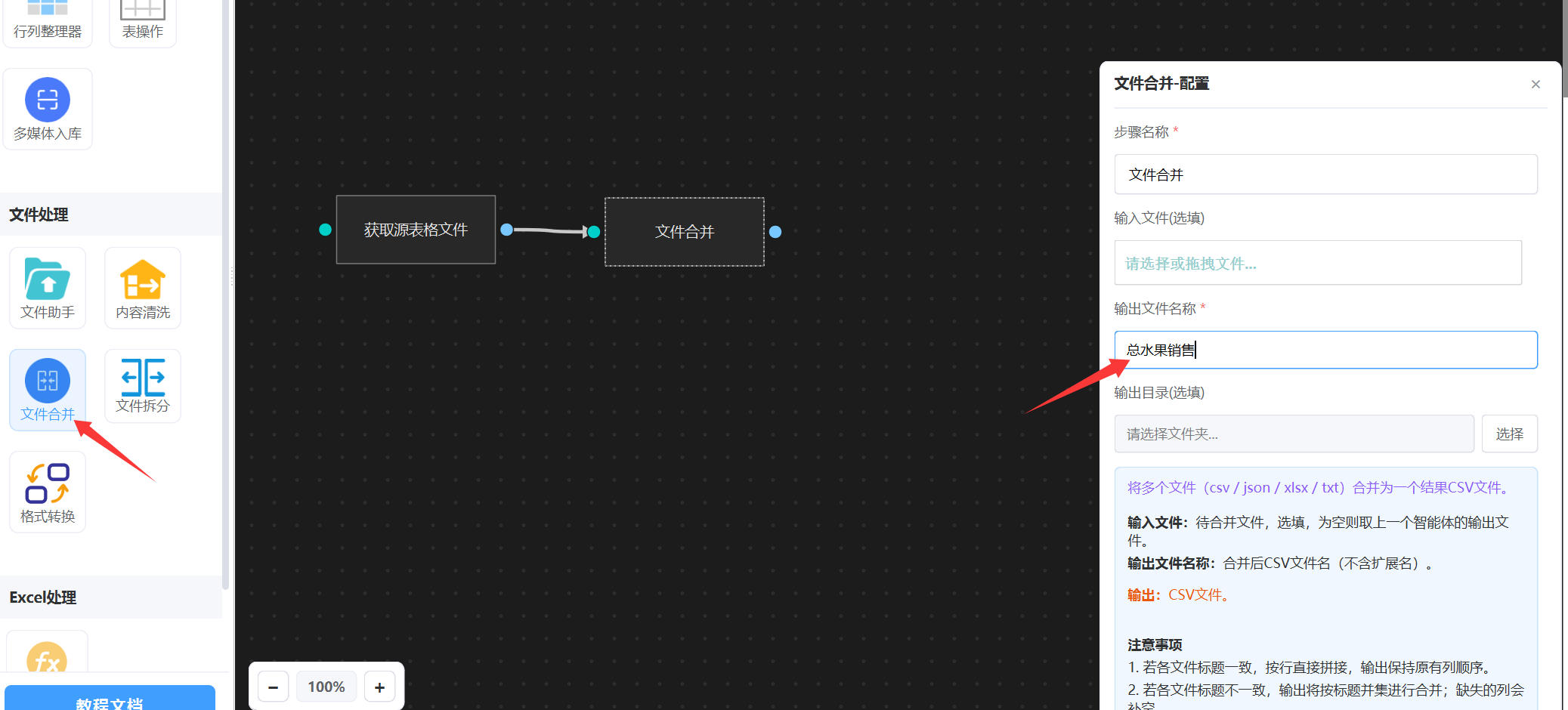
通过“文件合并”,就把原始表格合成成了一个大的csv表格文件,名称叫“总水果销售”。
步骤3: 清理异常数据 + 新增列
找到“内容清洗”, 这个是专门对表格的行,列进行操作的智能体,提示词如下图:
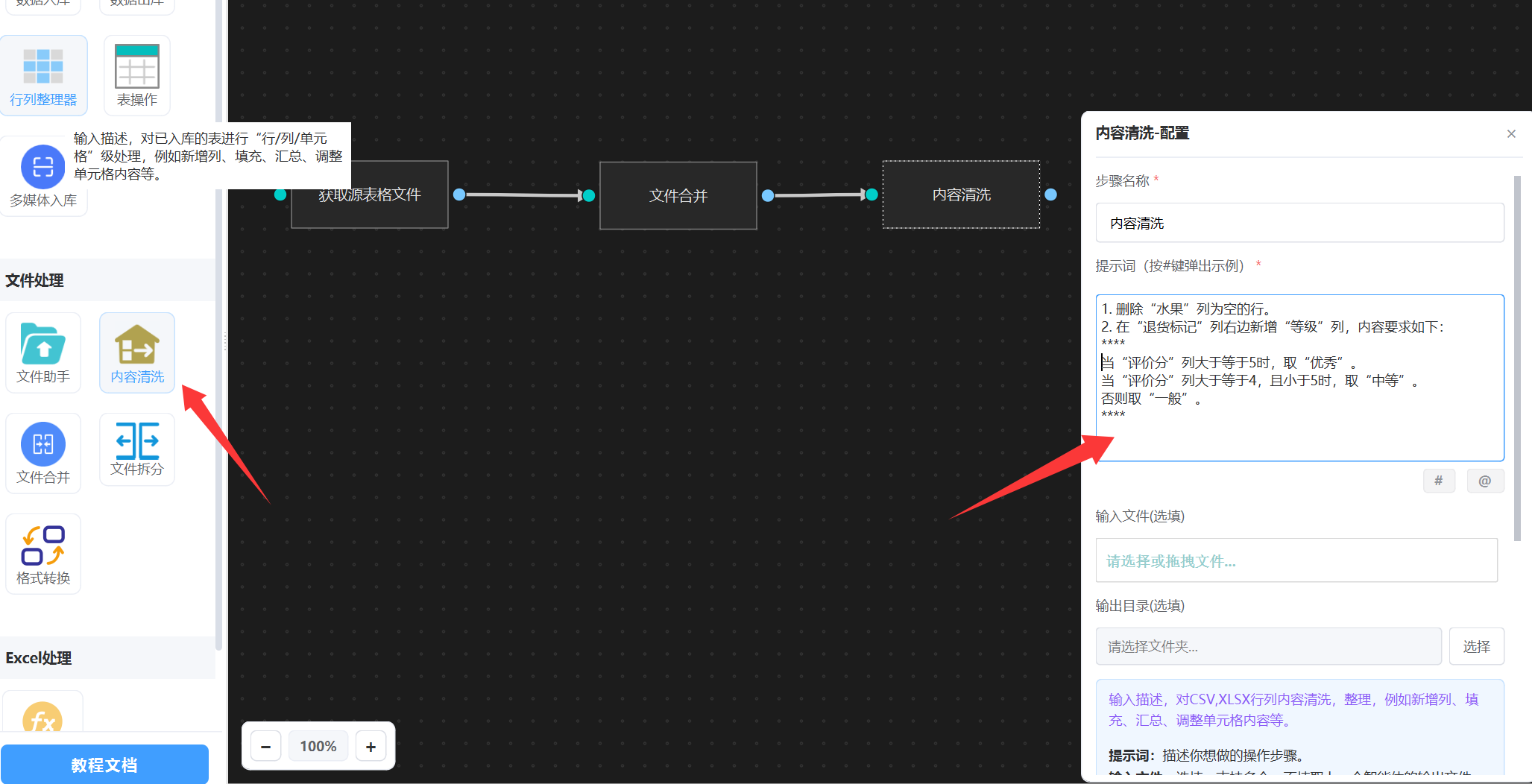
我们配置了2个步骤 , 并且描述清除了每个步骤的具体内容。
步骤4: 数据入库
当我们把文件的数据清理好之后,接下来就是统计了,统计需要先进入入库生成表。找到“数据入库”,如下图:
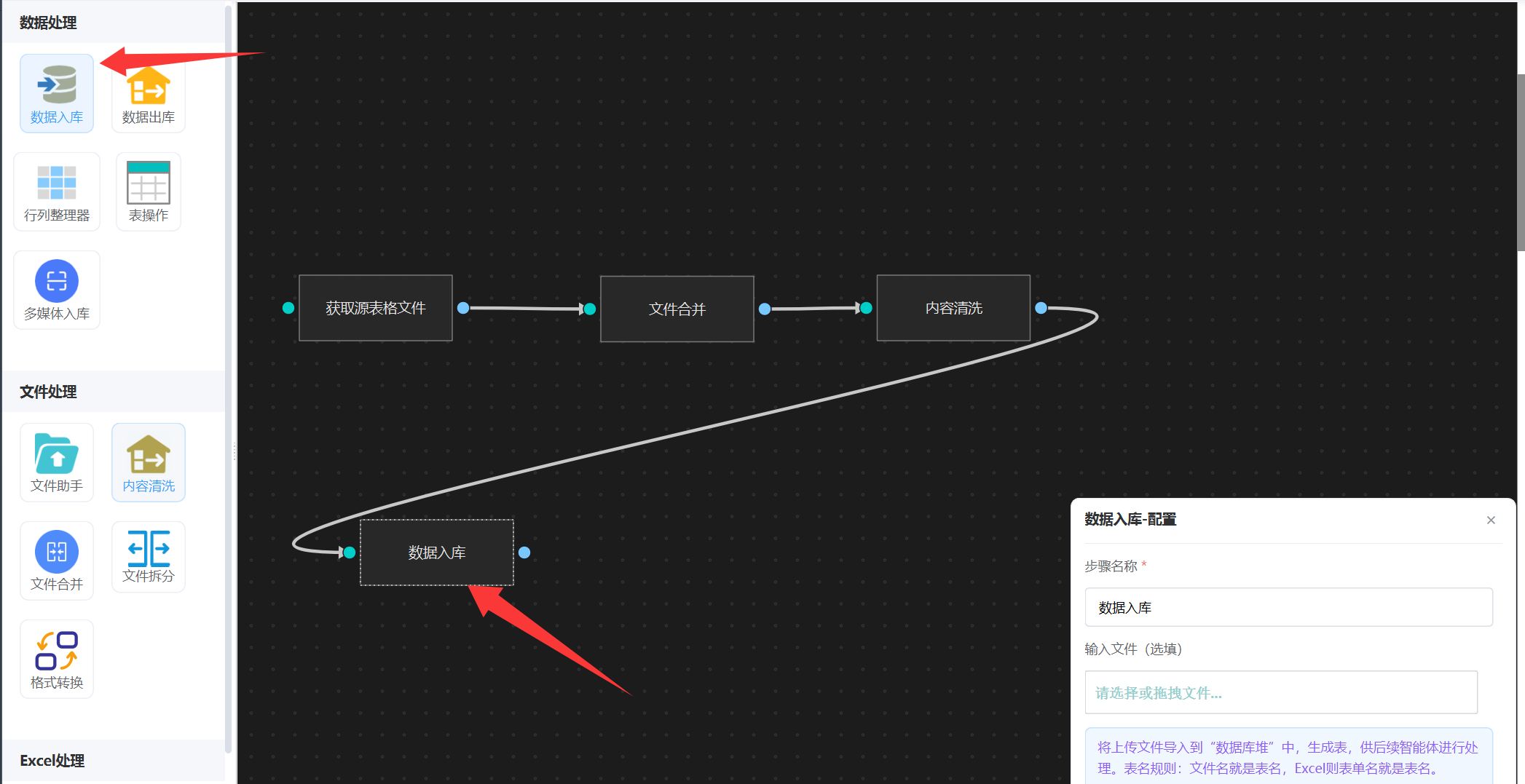
步骤5: 分组统计
找到“表操作”,配置好统计的提示词和输出表名,如下图:
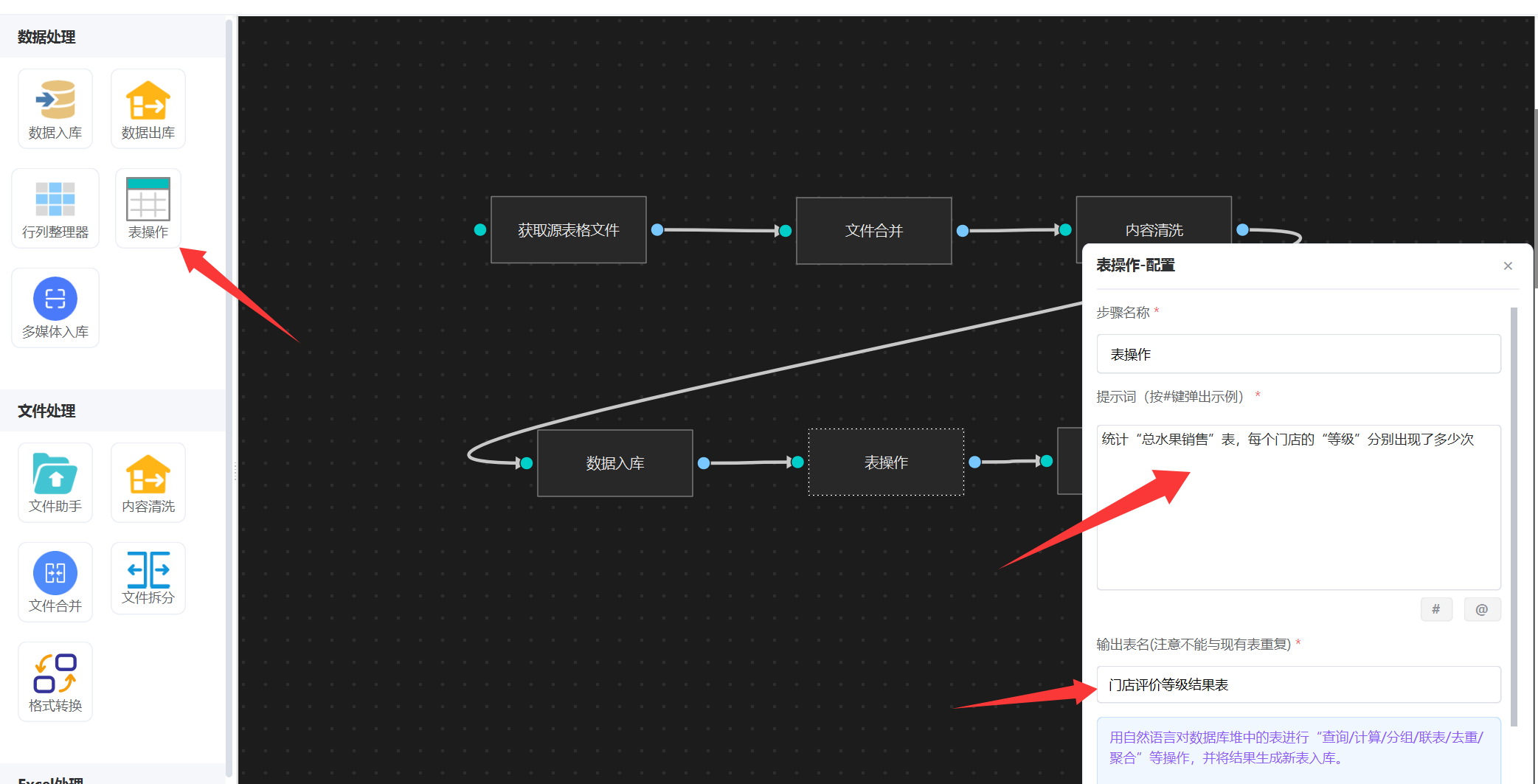
注意提示词里面,一定要描述对哪张表进行统计, 表的名称就是 文件合并你填写的文件名称。
输出表名一定要填写。
步骤6: 数据出库
找到“数据出库”,选择你要出库的表,如下图:
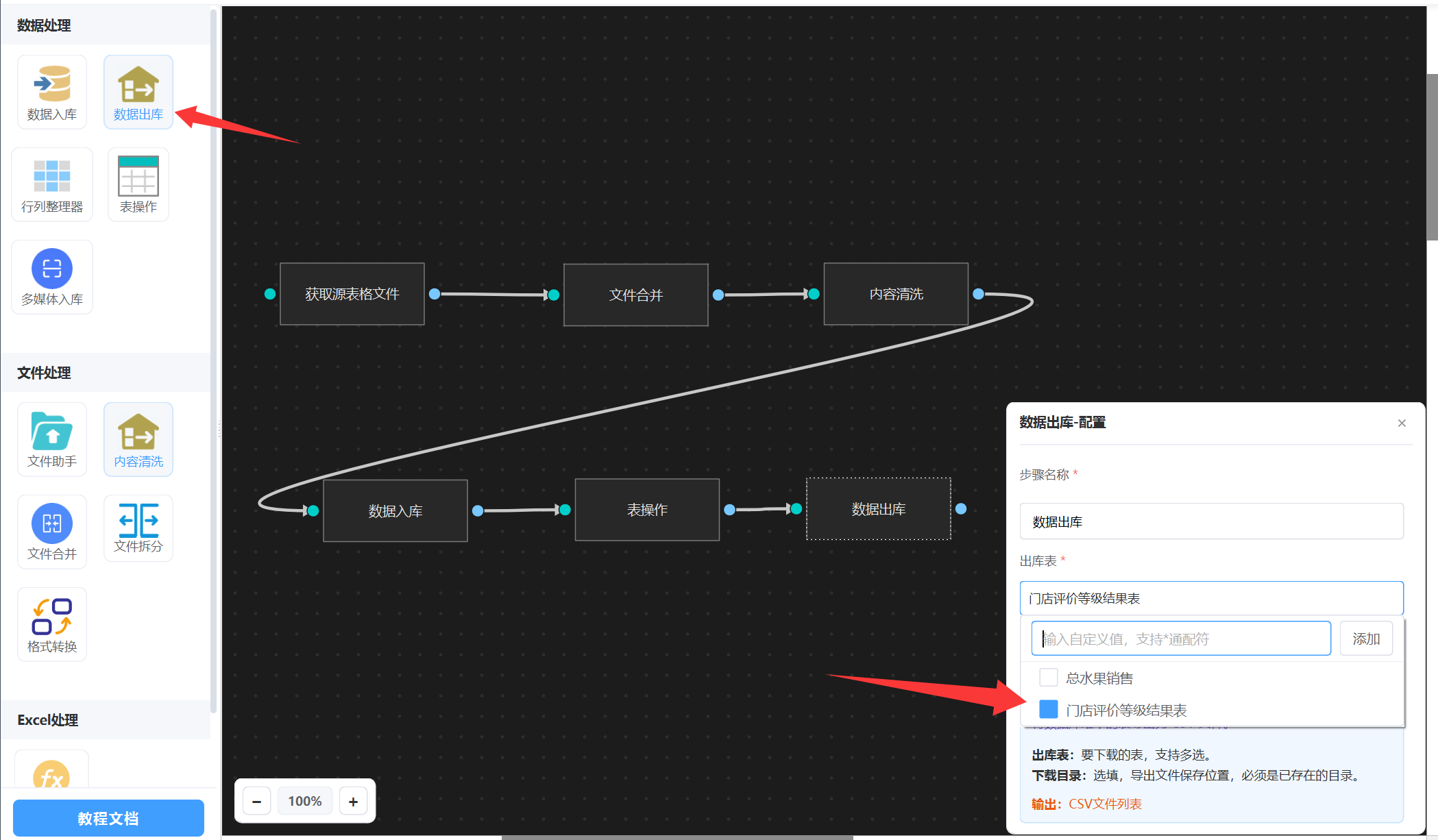
出库后,就会把数据存储到csv文件。
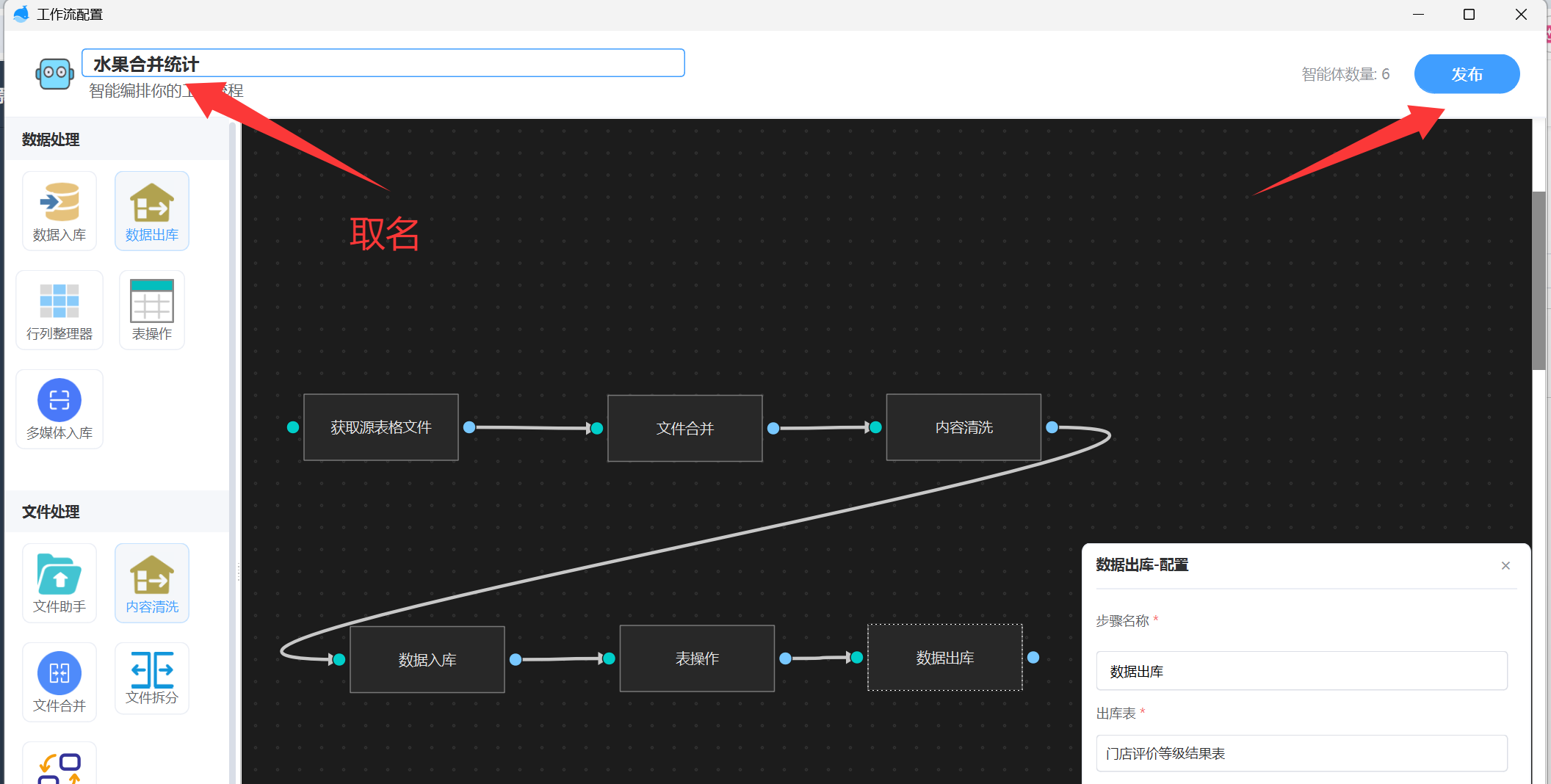
到此,我们工作流就配置完成,跟工作流取一个名称,然后发布就行了。如下图:
三、运行工作流
找到配置的工作流,点击启动:
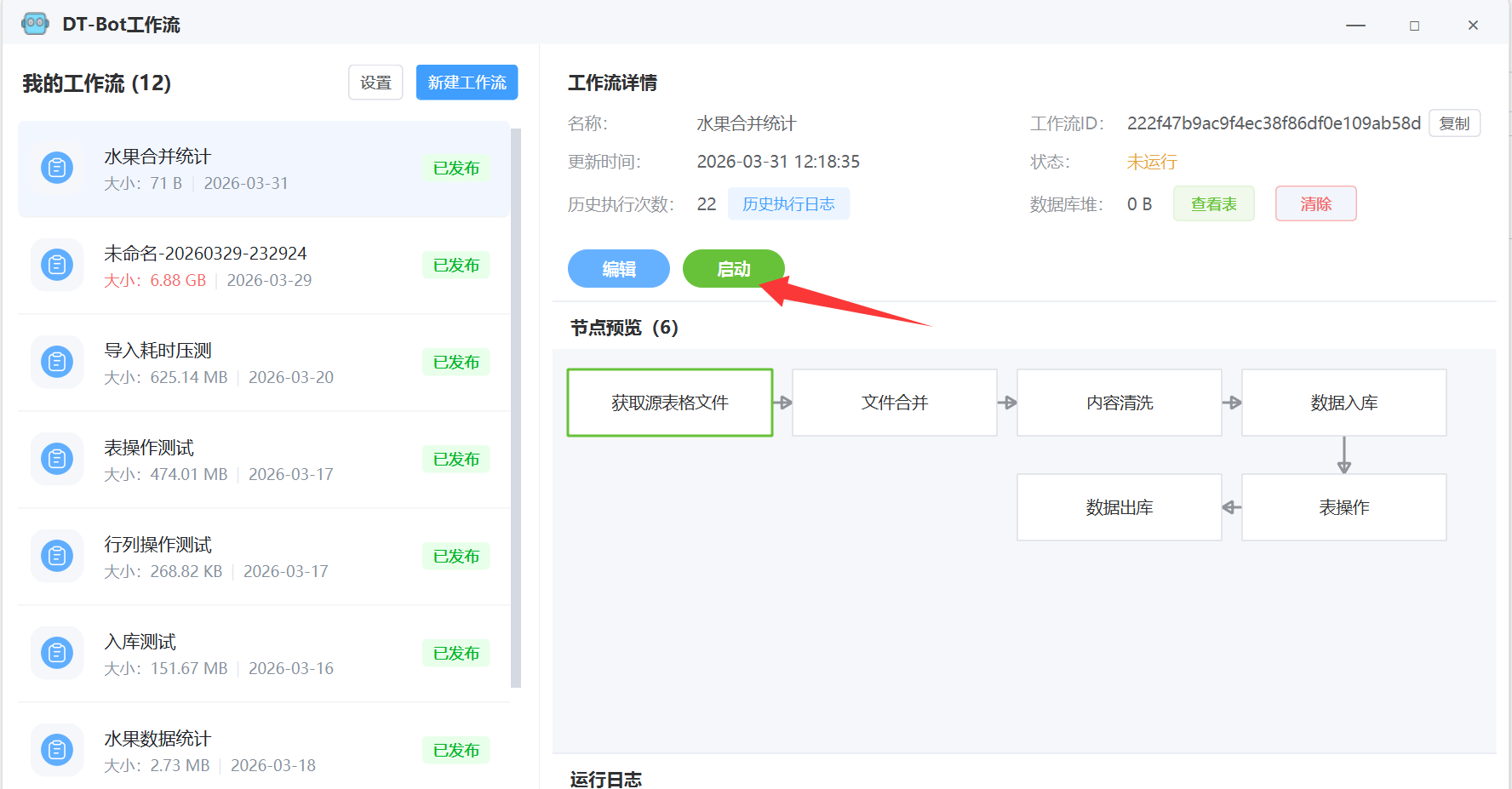
等待运行结果, 注意,当程序在前台时,运行的速度很快! 如果切换到后台,可能cpu资源分配不足,导致运行速度很慢。
四、获取结果
等待工作流执行完成后,可以在最后一个节点右键,预览结果:
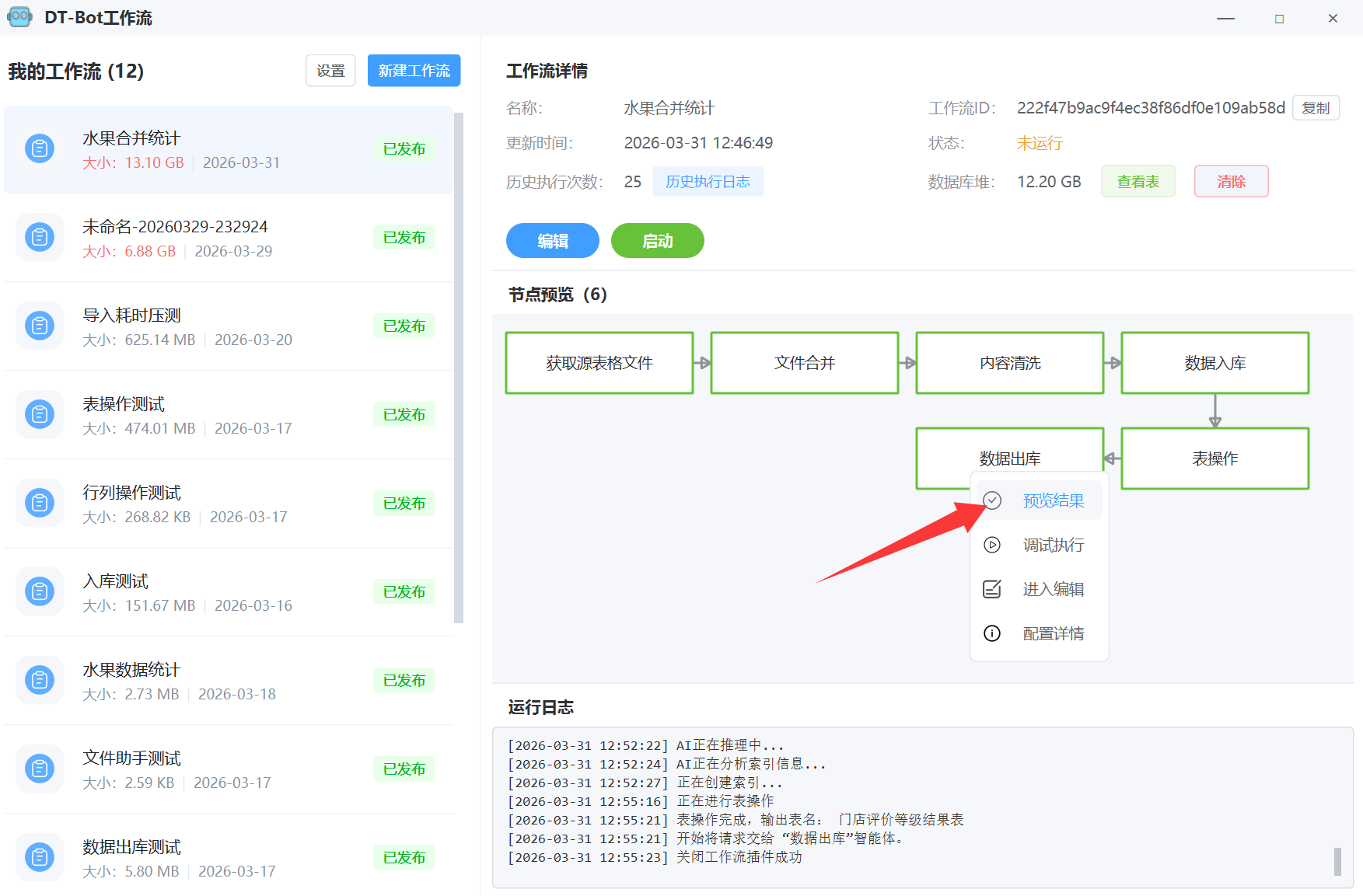
打开目录就可以看到结果源文件了。
五、总结
本案例针对1000万行销售数据,通过6步工作流(文件获取→合并→清洗→入库→分组统计→出库),实现多表合并、异常清理、按评价分划分等级(优秀/中等/一般),并最终统计每个门店各等级的出现次数。注意程序前台运行速度更快,后台可能因资源分配不足而变慢。