DTBot 的“多媒体入库”,可以将非结构化/媒体文件(图片、PDF、HTML、MD、DOCX)通过提示词描述提取关键信息进行入库,比如:提取图片的身份证号码,姓名等。
一、配置以及输入输出说明
在工作流编辑界面中,位于左侧 「数据处理」 分类下的 「多媒体入库」 节点,即为目前支持的入库智能体。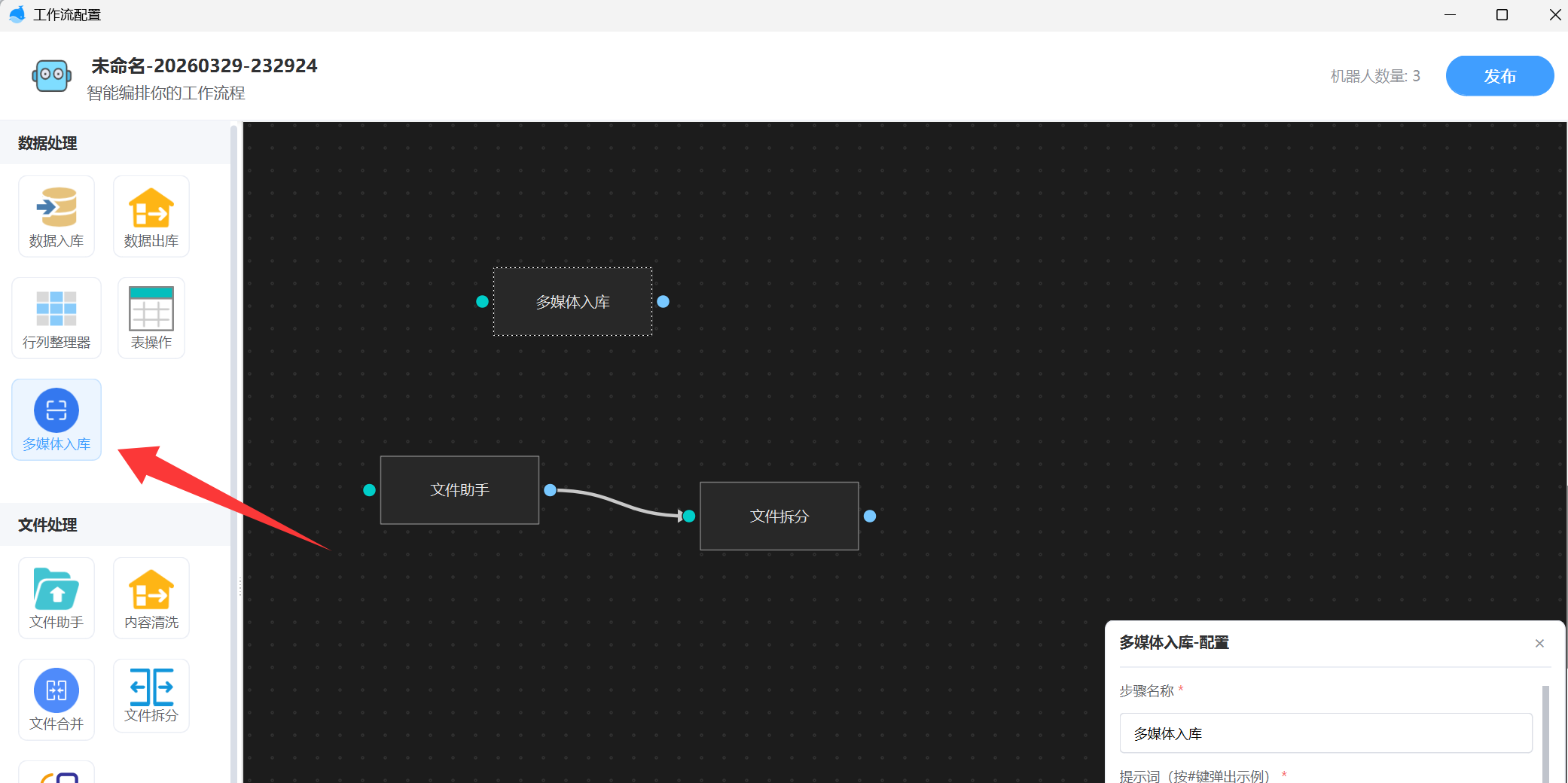
输入参数
- 提示词: 提取的描述提示词。
- 输入文件: 选填,待识别的媒体文件,支持多个,不填就取上一个智能体的输出文件。
- 输出表名: 入库的表名称。不能与现有表重复。
输出
输出表到数据库堆,无文件输出。
执行完入库后,可以查看到数据库堆的表情况。
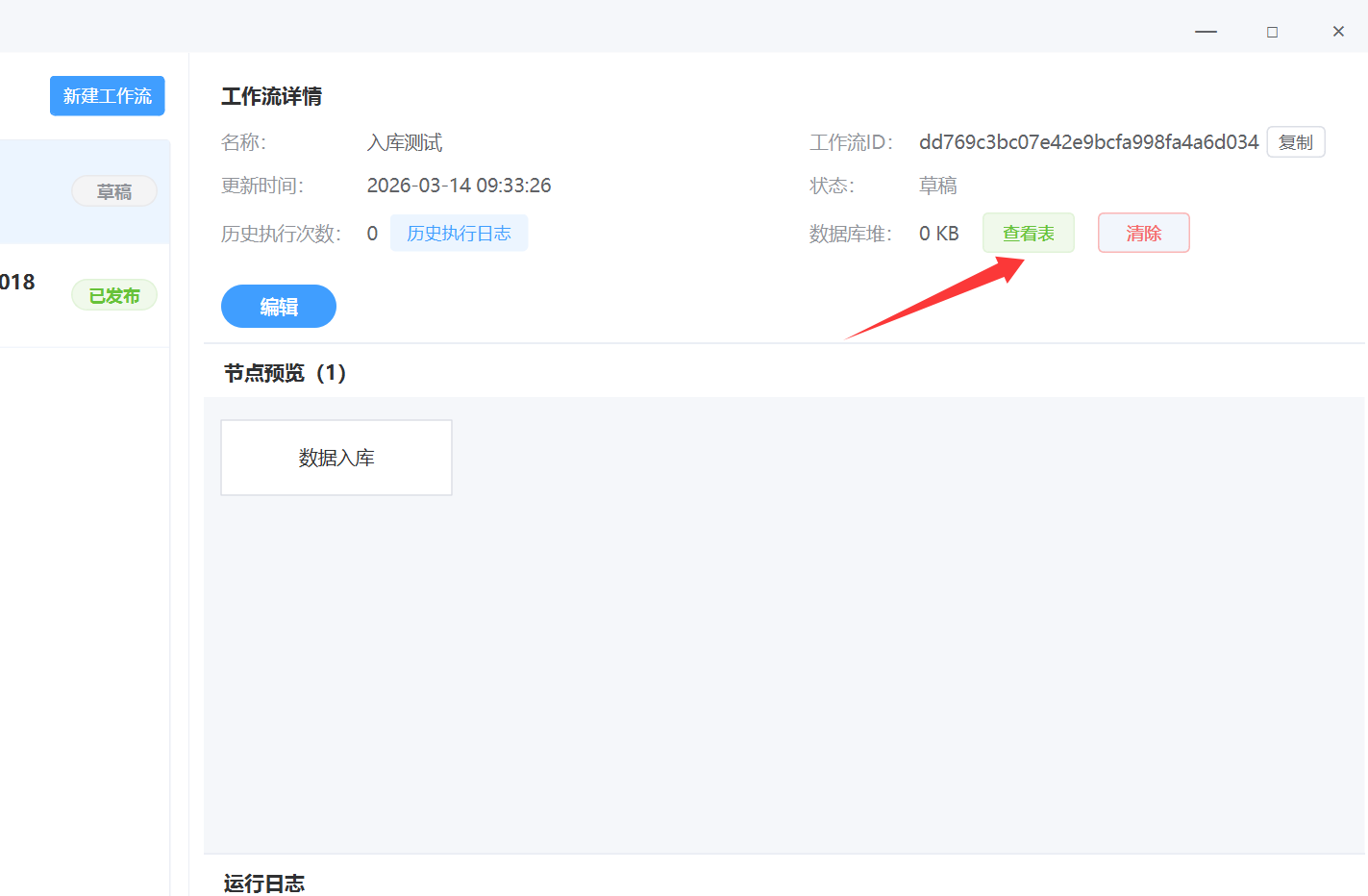
二、案例
媒体文件包括:图片、PDF(含图片与文字)、HTML、MD、WORD 文档。这类文件不具备二维行列结构,本质为非结构化内容。
因此,媒体文件入库时需通过提示词(Prompt)引导模型进行信息抽取,将其转化为二维行列结构。
下面为一个身份证提取的案例:
请根据下面规则提取字段:“姓名,性别,民族,出生日期,住址,身份证号码,签发机关,证件有效期”。
## 一、姓名
规则:
1. 识别证件正面“姓名”字段内容
2. 保留原始姓名全称,不做简写或拆分
3. 姓名中含少数民族姓名空格或特殊符号时需保留
输出示例:
阿依努尔·艾合买提
## 二、性别
规则:
1. 优先识别字段“性别”内容
2. 仅输出“男”或“女”,不输出“性别:男”
3. 模糊时以身份证号第17位奇偶校验补充判断(奇数为男,偶数为女)
输出示例:
男
## 三、民族
规则:
1. 识别字段“民族”内容
2. 统一输出民族名称(如“汉”“维吾尔”“蒙古”)
3. 不输出“族”字(如“汉族”统一输出“汉”)
输出示例:
汉
## 四、出生日期
规则:
1. 识别“出生”字段日期
2. 统一转为标准格式:YYYY-MM-DD
3. 若原文为“1990年3月2日”→“1990-03-02”
4. 若只识别到年月,默认补“01”
输出示例:
1990-03-02
## 五、住址
规则:
1. 识别“住址”字段全部内容
2. 保留省市区县街道门牌等完整信息
3. 多行住址需合并为一行输出
4. 不要删减或纠错地址
输出示例:
广东省深圳市南山区科技园南区1号楼502室
## 六、身份证号码
规则:
1. 识别18位身份证号码,需完整保留
2. 若末位为“X”,需保持大写
3. 防止“0/O”“1/I”“2/Z”误识
4. 若号码缺失或不完整,输出“【未识别到】”并提示需补拍
输出示例:
440301199003021234
## 七、签发机关
规则:
1. 识别“签发机关”字段内容
2. 保留全称,如“深圳市公安局南山分局”
3. 不做简写
输出示例:
深圳市公安局南山分局
## 八、证件有效期
规则:
1. 识别“有效期限/有效期”字段
2. 统一格式:YYYY-MM-DD 至 YYYY-MM-DD
3. 若为长期有效,输出“长期”
4. 若只识别到开始日期,结束日期标注“【未识别到】”
输出示例:
2018-06-01 至 2038-06-01 或 长期下面为车牌号的提取案例:
请根据下面规则提取字段:“车牌号,车牌颜色,是否新能源”。
## 一、车牌号
规则:
识别车牌图像中的号牌号码
保留完整车牌号,包括汉字、字母和数字
格式如:京A12345、沪B88888、粤CD12345
注意区分字母与数字的相似字符(如“0/O”“1/I”“2/Z”)
若车牌污损或遮挡导致识别不全,输出“【部分遮挡】+可识别部分”
输出示例:
京A12345
## 二、车牌颜色
规则:
根据图像识别车牌底色
输出标准颜色分类:蓝、黄、绿、白、黑
颜色说明:
蓝色:普通燃油车
黄色:大型车辆、驾校车辆
绿色:新能源车(小型车绿底黑字,大型车绿底黄字或渐变绿)
白色:警用车辆、军用车辆
黑色:涉外车辆(外资企业、外籍人士)
若颜色模糊无法判断,输出“【无法识别】”
输出示例:
蓝
## 三、是否新能源
规则:
综合车牌号和车牌颜色判断
判断依据:
车牌颜色为绿色 → 是
车牌为6位号码(不含汉字),小型车第二位为字母D/F,大型车末位为D/F → 是
其他情况 → 否
输出“是”或“否”
输出示例:
否✨小秘诀 : 这些提示词千万不要自己傻傻的写。都可以直接交给AI来生成,比如我拿到DeepSeek里面:
三、总结
DTBot 的“多媒体入库”智能体是一款基于自然语言驱动的非结构化数据提取与入库工具,用户只需输入提示词,即可从图片、PDF、HTML、MD、DOCX 等媒体文件中提取关键信息并入库至数据库堆,无需编写代码;配置上支持多文件输入与自定义输出表名,执行后生成数据库表而非文件输出。使用时需通过提示词明确提取字段及规则,如身份证的姓名、性别、号码等信息或车牌号、车牌颜色等场景,提示词越具体、规则越清晰,提取效果越稳定。该工具适用于从非结构化内容中抽取结构化信息的场景,且提示词可由 AI 辅助生成,提升使用效率。